LH.pl · Dział pomocy



Content is the king? Zdecydowanie nadal jest to aktualne, jednak wypozycjonowanie strony, która będzie miała wartościową, długą i oczywiście unikalną treść nie zawsze jest takie proste. Dlaczego? Ponieważ algorytmy Google są dużo bardziej złożone i biorą pod uwagę znacznie więcej czynników, niż tylko kilka podstawowych elementów jak title, nagłówki czy zewnętrzne odnośniki prowadzące do witryny. Właśnie dlatego w tym artykule skupiłam się na technicznych aspektach SEO i przygotowałam listę 13 elementów, o których warto pamiętać.
Spis treści
pokaż
13 elementów technicznego SEO, o których warto pamiętać
1. Tag meta robots
Być może wiele osób potraktuje ten element jako banał… Tak, jest to podstawa podstaw, jednak jeśli Twój tag meta robots został ustawiony inaczej niż “index, follow” – będziesz mieć trudności z indeksacją strony. Zdarzają się sytuacje, gdy np. dla świeżo wdrożonej nowej wersji strony developer nie usunie “noindex” po wdrożeniu wersji developerskiej na produkcję. Co się stanie w takiej sytuacji? Zazwyczaj Google przez pewien czas trzyma starą stronę w swojej “pamięci” i nadal wyświetla ją w wynikach wyszukiwania – nie zobaczy on jednak wprowadzonych zmian. A jeśli projekt byłby całkowicie nowy, strona nie zostałaby zaindeksowana i nie byłaby wyświetlana w Google.
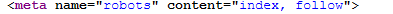
2. Plik robots.txt
Robots.txt to niepozorny plik, którego nie widać na stronie, a jednocześnie ma on ogromne znaczenie pod kątem SEO. Jego celem jest określenie sposobu poruszania się po stronie botów, w tym Googlebota. Dzięki niemu możemy wskazać, które strony chcielibyśmy, aby były indeksowane, w które nie. Ten plik powinna posiadać KAŻDA domena.
Dalej zastanawiasz się, po co Ci ten plik? Pamiętaj, że Googlebot ma ograniczone zasoby – jeśli będzie indeksować mało istotne strony, może zabraknąć jego zasobów na te ważniejsze. Właśnie dlatego powinieneś określić, czy chcesz, aby Twoja strona była indeksowana, a także określić jakie strony chcesz pominąć. Dużym ułatwieniem jest tutaj możliwość korzystania z wzorców, np. możesz wykluczyć adresy URL zawierające określoną ścieżkę lub parametr.
Pamiętaj jednak, że jeden niewłaściwy zapis w pliku robots.txt może skutkować wyindeksowaniem całości witryny lub cześci stron. Jeśli nie jesteś pewien czy został on utworzony poprawnie, możesz wykorzystać tester pliku robots.txt od Google Search Console.
Plik robots.txt zawsze znajduje się pod adresem twojadomena.pl/robots.txt.

3. Sitemap.xml
To kolejny plik, który nie jest przeznaczony dla użytkowników, a dla botów. Stanowi pewnego rodzaju listę zawierającą wszystkie adresy URL, które chcemy pokazywać w Google.
Mapa witryny (bo tym właśnie jest plik sitemap.xml) ma ułatwiać robotom, oczywiście w szczególności Googlebotowi, poruszanie się po stronie i indeksowanie poszczególnych zasobów, aby później mogły one pojawiać się w wyszukiwarce.
Dobrą praktyką jest tworzenie kilku map witryny i agregowanie ich w jednym indeksie sitemap. Są 3 podstawowe powody, dlaczego sitemapy dzielimy na kilka plików:
● Twoja strona jest bardzo duża i chcesz umieścić w niej więcej niż 50 000 adresów URL;
● masz kilka wersji językowych i chcesz śledzić ich stan zaindeksowania osobno;
● chcesz śledzić osobno indeksację dla określonych typów stron (np. osobno produktów, osobno blogpostów) lub określonych obszarów strony (np. w przypadku sklepów internetowych wydzielając całą sekcję strony, która dotyczy konkretnej grupy asortymentu).
Wydzielenie osobnych sitemap ma kilka zalet, spośród których jedną z najważniejszych jest to, że możemy osobno analizować ich stan indeksacji. Dlaczego jest to istotne? Przede wszystkim dlatego, że możesz wykryć słabsze obszary swojej strony i nad nimi popracować, aby zwiększyć indeksację.
Mapa witryny nie musi znajdować się zawsze pod tym samym adresem – niektóre systemy CMS i wtyczki/moduły wykorzystywane do generowania sitemap umieszczają je pod indywidualnymi adresami. Ważne jest, aby podać adres mapy witryny w Google Search Console. Tam również możemy sprawdzić jej stan.
4. Adresy kanoniczne
Nie jest to absolutny must-have dla każdej strony, ale warto wiedzieć o ich istnieniu, wiedzieć, kiedy warto je wprowadzić i umieć wykryć ewentualne błędy w ich konfiguracji. Kiedy canonicale mogą okazać się przydatne?
Przede wszystkim wtedy, gdy treść na Twojej stronie jest zduplikowana. Jeśli wykorzystujesz ją na kilku stronach, które dotyczą tego samego – adres kanoniczny pozwala Ci określić oryginał. Dzięki temu unikniesz niepożądanego zjawiska kanibalizacji i zmniejszysz poziom duplikacji wewnętrznej. Przydatne są także wtedy, gdy utworzonych jest wiele małowartościowych stron o podobnej tematyce.
Pamiętaj, że zastosowanie canonicala wskazującego inny adres niż bieżący może spowodować jego wyindeksowanie. Niewątpliwym plusem jednak jest fakt, że strona będzie nadal dostępna dla użytkowników i będzie mogła być wyświetlona – w przeciwieństwie do sytuacji, gdybyśmy zastosowali przekierowanie.
Canonicale często są wykorzystywane w przypadku zastosowania filtrów, których indeksować nie chcemy. W przypadku zmiany domeny można również wykorzystać canonicale – szczególnie w początkowej fazie. Jest to mniej “drastyczne” rozwiązanie niż wprowadzenie przekierowania. Stara strona będzie nadal dostępna, jednak powoli będzie ona przenoszona na nowy adres.

Warto wiedzieć także, że Google od pewnego czasu faworyzuje canonicale i zaleca ich wprowadzanie zamiast przekierowań.
Kiedy nie potrzebuję canonicali? Jeśli masz prostą stronę i nie widzisz problemów ze stanem indeksacji swojej strony, nie masz duplikacji wewnętrznej treści, nie będziesz ich potrzebował 🙂 Jeśli jednak prowadzisz dużą stronę, o skomplikowanej strukturze i chcesz mieć lepszą kontrolę nad indeksacją, z czasem będziesz musiał zmierzyć się z tematem ich wdrożenia.
5. Hreflangi
Można je oczywiście wdrożyć na każdej stronie, jednak sens mają głównie wtedy, gdy strona jest wielojęzyczna.
Co to jest? Rolą hreflangów jest wskazanie Google alternatywnych wersji strony wraz z określeniem, dla których użytkowników mają one być wyświetlane – w zależności od ich kraju pobytu oraz języka przeglądarki.
Kiedy warto? Zawsze, gdy mamy kilka wersji językowych strony – również wtedy, kiedy znajdują się one na różnych domenach. Warto pamiętać także o definiowaniu wartości hreflang x-default, który wskazuje domyślną wersję językową. Zostanie ona wyświetlona użytkownikom, dla których nie zdefiniowaliśmy dedykowanej wersji językowej.
Przykład: Nasza strona jest dostępna tylko w polskiej i angielskiej wersji językowej. Użytkownik niemieckojęzyczny natrafia w Google na naszą stronę – którą wersję językową powinien otrzymać? Jeśli zdefiniujemy hreflang x-default na wersję angielską, właśnie ją zobaczy.
Hreflangi będą szczególnie ważne w krajach wielojęzycznych oraz w przypadku, gdy kierujemy swoją ofertę do osób znajdujących się poza swoim krajem zamieszkania.
6. Certyfikat SSL
Posiadanie certyfikatu SSL jest jednym z czynników rankingowych Google – witryny, które go posiadają cieszą się większym zaufaniem zarówno Google, jak i użytkowników. Co daje certyfikat SSL? Dzięki niemu dane przesyłane są w sposób zaszyfrowany, co zwiększa ich bezpieczeństwo.
Szczególnie istotne jest to oczywiście w przypadku sklepów internetowych – jako użytkownicy podajemy swoje dane osobowe, kontaktowe, adresowe, a czasem nawet dane karty płatniczej. Nie chcemy przecież, aby trafiły one w niepowołane ręce. Jednak nie tylko sklepy internetowe powinny mieć certyfikat bezpieczeństwa – wymagać go można także od stron, które posiadają formularze kontaktowe. W końcu chcemy, aby odezwała się do nas konkretna firma, a nie aby nasze dane kontaktowe trafiły do oszustów, którzy będą mogli się próbować pod nią podszyć.
Wydawać by się mogło, że to standard w dzisiejszych czasach, ale niestety wiele stron nadal go nie posiada lub jego wdrożenie nie jest w pełni poprawne. Jego zainstalowanie najprościej można rozpoznać po wyświetleniu się w pasku adresu w przeglądarce protokołu https oraz symbolu zamkniętej kłódki.

A co jeśli symboliczna kłódka nie jest zamknięta lub jest przekreślona? Zazwyczaj oznacza to, że certyfikat nie jest wprowadzony w pełni poprawnie. Często naprawa tej kwestii wymaga kilku szybkich zmian w kodzie strony.
Nie zapominaj o przedłużeniu ważności certyfikatu – często wykupywany jest on np. na rok. Pamiętaj o tym, że poszczególne protokoły strony są na siebie przekierowane i w momencie wyłączenia certyfikatu SSL użytkownicy otrzymają komunikat o możliwym niebezpieczeństwie i najpewniej ją opuszczą. Szanujmy ruch na swojej stronie i nie dopuszczajmy do takich sytuacji.
Dobra wiadomość jest jeszcze taka, że dla niewielkich stron prosty certyfikat SSL można wdrożyć nawet za darmo!
7. Przekierowania
Mając stronę internetową należy zdecydować się na 1 protokół, pod którym będzie ona dostępna. Najlepiej, aby witryna była zabezpieczona SSL’em, więc postawmy na https – natomiast mamy dowolność odnośnie zastosowania protokołu www. Niezależnie od wybranego protokołu, pozostałe 3 (w przypadku domen z https, 1 w przypadku http) powinny być przekierowane za pomocą 1 przekierowania stałego 301 na docelowy adres, z odpowiednim protokołem.
Ważne jest, aby mieć świadomość, że są różne typy przekierowań, a jego wybór nie jest bez znaczenia dla SEO. Najczęściej spotykane są dwa podstawowe przekierowania – 301 i 302:
● przekierowanie 301 – jest to przekierowanie stałe, które sugeruje Google, że całą moc strony, na której jest wywoływane przekierowanie należy przenieść na nowy adres.
● przekierowanie 302 – jest to przekierowanie tymczasowe, które może sugerować, że na stronie wprowadzane są obecnie jakieś zmiany i niedługo przekierowanie to zostanie zmienione. Często przekierowania 302 wprowadza się w formie testu, przed wprowadzeniem przekierowania 301, aby sprawdzić poprawność wdrożenia.
O temacie przekierowań nie można zapominać także w przypadku zmiany strony, jej struktury czy zmiany domeny.
8. Przyjazne adresy URL
Przy konfiguracji sposobu tworzenia adresów URL warto kierować się… prostotą. Dobry adres URL jest możliwie krótki, można go nawet przedyktować, a jednocześnie powinien celnie określać miejsce, gdzie znajduje się użytkownik.
Podstawowa zasada jest taka, że stosujemy wyłącznie znaki alfanumeryczne bez polskich znaków i myślnik. Myślnik zastępuje nam spację między wyrazami. Do adresu URL można wprowadzić dodatkowe ścieżki (katalogi), ale należy robić to świadomie. Nie można przesadzać z ich liczbą, ponieważ pod kątem SEO – im bliżej słowo kluczowe zajmuje się początku adresu URL tym lepiej.
9. Błędy 404
Ten punkt dotyczy nie tyle samych błędów 404, co zaprojektowania rozwiązań, które pozwolą sobie z nimi radzić.
Błędy 404 “strony nie znaleziono” występują najczęściej po:
● przebudowie strony/migracji,
● usunięciu stron/produktów.
Występowanie błędów 404 może prowadzić do zmniejszenia się ruchu na stronie – dlatego bardzo rozważnie trzeba podchodzić do usuwania zasobów ze strony.
Najbardziej uniwersalnym sposobem radzenia sobie z błędami 404 jest wdrożenie przekierowań 301. Trzeba natomiast pamiętać o tym, że dla każdego istotnego usuwanego zasobu trzeba wskazać nowy adres, na który powinien trafić użytkownik. Te nowe strony, na które będziemy kierować przekierowany ruch należy dobierać tak, aby były możliwie najbardziej zbliżone do tych usuniętych – nie chcemy przecież, żeby użytkownik poczuł się oszukany i szukając np. etui do określonego modelu telefonu trafił na stronę etui do innego modelu.
Z kolei usuwanie produktów bardzo często jest związane z ich niedostępnością – nie ma już produktu i nie jest planowana jego dostawa. Jeśli występuje taka sytuacja, można rozważyć pozostawienie go w systemie i wprowadzenie sekcji “tego produktu już nie ma w ofercie, ale zobacz produkty podobne” i wyświetlić z nimi listing. Drugą opcją jest oczywiście usunięcie produktu i wprowadzenie przekierowania 301 (najlepiej na podobny produkt, ewentualnie na stronę kategorii/ producenta, w ostateczności na stronę główną).
10. Wersja responsywna
W dzisiejszych czasach już chyba nikogo nie trzeba przekonywać do tego, że strona powinna być zaprojektowana z myślą o jej poprawnym wyświetlaniu na urządzeniach mobilnych. Możemy stworzyć dedykowaną wersję mobilną, postawić na AMP lub zdecydować się na wersję responsywną. Największą popularnością cieszy się ta ostatnia z uwagi na łatwość jej późniejszego zarządzania – mamy 1 stronę, która po prostu dostosowuje się do wielkości ekranu.
Wdrażając nowe elementy na stronie – nie zapominaj o sprawdzeniu ich funkcjonowania na urządzeniach mobilnych. Niejednokrotnie widywałam u swoich Klientów pop-up, którego nie można było zamknąć lub menu się nie rozwijało. Oczywiście na komputerach wszystko działało poprawnie.
Dbaj o responsywność strony – szczególnie warto sprawdzić sposób jej wyświetlania na urządzeniach mobilnych po wdrożeniu obrazków czy tabel. Jeśli prowadzisz sklep internetowy, przejdź przez cały proces transakcji, aby zobaczyć czy w ogóle złożenie zamówienia jest możliwe na mobile. Jeśli masz stronę usługową – koniecznie wypełnij testowo formularz.
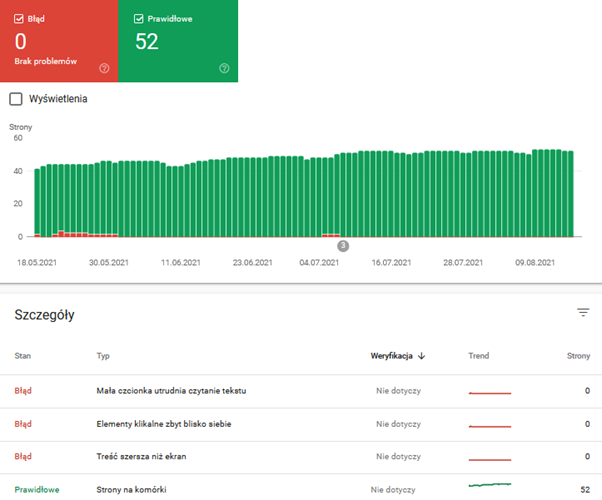
Zadbaj też o komfort czytania, upewnij się, że wielkość fontu jest odpowiednia, a elementy klikalne nie znajdują się zbyt blisko siebie. Takie elementy również są analizowane przez Google.
Nie ukrywaj treści, czy nagłówków na urządzeniach mobilnych. To ma ogromne znaczenie pod kątem SEO! Pamiętaj, że “mobile first” odnosi się nie tylko do projektowania strony, ale obecnie również do indeksowania stron przez Google.
11. Czas ładowania strony & Core Web Vitals
Czas ładowania strony również jest jednym z czynników rankingowych Google. Bardzo popularnym narzędziem służącym do jego analizy jest PageSpeed Insights. Jego wyniki nie są jednak proporcjonalnie skorelowane z pozycjami czy ruchem organicznym – poprawa wyników o 1 pkt prawdopodobnie nie przełoży się w ogóle na wyniki.
O co więc chodzi?
Przede wszystkim o to, żeby strona ładowała się w miarę szybko, szybko reagowała na nasze interakcje i działała stabilnie. Jeśli wyniki analiz tych elementów będą słabe, możemy spodziewać się spadku pozycji i ruchu organicznego. Jeśli popracujemy nad poprawą wyników i sami będziemy zauważać, że strona funkcjonuje lepiej, Google z pewnością niedługo to doceni.
Częste rekomendacje w tym zakresie dotyczą: wdrożenia asynchronicznego ładowania css i js, włączenie kompresji tekstu, wdrożenie cache’a, ograniczenia zewnętrznych skryptów (wtyczek), zmniejszenia wagi zdjęć i /lub ich typu.
Niesposób tutaj nie wspomnieć o Core Web Vitals. W ich skład wchodzą trzy główne wskaźniki: LCP, CLS i FID.
● LCP – wskaźnik dotyczący czasu potrzebnego na załadowanie największego elementu na stronie (pomiar odbywa się w części above-the-fold). Ma on dodatkowo wspomóc ocenę czasu ładowania się strony.
● CLS – wskaźnik dotyczący stabilności, a dokładniej przesunięć układu strony. Na pewno nieraz zdarzyło Ci się chcieć kliknąć w pewien element, a przez doładowanie innego elementu został on przesunięty i kliknąłeś w coś innego. Poprawa wskaźnika CLS ma służyć eliminacji takich sytuacji.
● FID – wskaźnik dotyczący interaktywności. Jego celem jest ocena, ile czasu na reakcję potrzebuje strona po pierwszej interakcji użytkownika.

Wszystkie te wskaźniki należy analizować zarówno dla wersji desktopowej, jak również dla urządzeń mobilnych – wyniki mogą być skrajnie różne.
12. Renderowanie i JS
Obecnie bardzo duża liczba stron wykorzystuje Java Script. Google twierdzi, że świetnie radzi sobie z jego interpretacją. I w zasadzie jest to prawda, jednak bardzo dużo zależy od właściwego wdrożenia elementów na stronie przez developera. Dlaczego?
Otóż podstawą, aby strona była dobrze interpretowana przez Google jest to, aby poszczególne elementy pojawiały się w kodzie strony. Mogą one oczywiście mieć chwilowo wyłączoną widoczność na stronie, ale zawsze powinny być tak zakodowane, aby określona akcja wywoływała ich wyświetlenie. Szczególnie istotne jest to w perspektywie ukrywanych treści, czy nagłówków. Jeśli decyduj esz się na ich ukrycie, sprawdź w źródle strony czy ukryty fragment się tam znajduje. Jeśli go tam nie ma, zgłoś poprawkę do developera.
Mimo, że Google jest w stanie zinterpretować ukryte treści, które dopiero później zostaną wyświetlone, często traktuje je jako mniej wartościowe niż te od razu widoczne. Warto mieć to na uwadze planując ukrywanie elementów.
Uważaj na to, aby Twoja strona bez obsługi Java Scriptu nie była pusta – możesz przetestować to wyłączając obsługę JS w przeglądarce.
Sprawdź także, jak strona wygląda w wyrenderowanej wersji. Możesz zobaczyć to np. w narzędziu Screaming Frog. Czasami okazuje się, że Googlebot nie ma dostępu do wszystkich niezbędnych zasobów (np. ma zablokowany dostęp w robots.txt).
13. Dane strukturalne
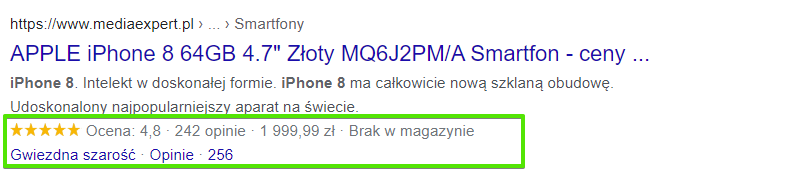
Pół żartem, pół serio można powiedzieć, że zadaniem danych strukturalnych jest pomoc Google w zrozumieniu świata. Ten ostatni omawiany element nie ma wpływu na pozycje w wynikach wyszukiwania, ale może mieć wpływ na ruch organiczny. Dlaczego? Dane strukturalne pozwalają nam na wyświetlenie w Google większej ilości informacji. Prowadzisz sklep internetowy? Pokaż od razu w Google cenę, opinie, czy dostępność. Prowadzisz bloga? Pokaż już w wynikach wyszukiwania, kiedy artykuł został opublikowany. Zapoznaj się koniecznie z możliwościami standardu Schema.
Podsumowanie
Koniecznie przeanalizuj swoją stronę pod kątem wspomnianych elementów. Oczywiście musisz mieć świadomość, że nie są to wszystkie techniczne aspekty SEO. Można byłoby ich wymienić dużo, dużo więcej, np. zarządzanie filtrami, paginacją, czy geolokalizacja. Jednak w tym artykule postawiłam na najważniejsze z nich w formie “zajawki” 🙂
Podobał Ci się artykuł? Zostaw opinię!
Jeden komentarz
Możliwość komentowania została wyłączona.






Sporo ważnych i czasami (niestety) zapominanych elementów optymalizacji/działań, które później rzutują bezpośrednio na efekty SEO.
Pozdrawiam,
Piotr